Es gibt zahlreiche Werkzeuge zur optischen Zeichenerkennung (OCR = Optical Character Recognition), die seit rund 3 Jahrzehnten in der Industrie im Einsatz sind. Die neuen Methoden bedienen sich der künstlichen Intelligenz und basieren bei der Erkennung, d. h. beim Lesen, auf neuronalen Netzwerken oder speziellen Klassifikatoren.
Methoden für das maschinelle Lesen
Neuronale Netze wurden als Modelle für das menschliche Gehirn entwickelt. Dabei werden viele miteinander verbundene Logikblöcke (Neuronen), die in Schichten (Layer) angeordnet sind, miteinander verbunden. Es gibt eine Eingabeschicht (Input Layer), eine bestimmte Anzahl von Zwischenschichten (Hidden Layers) und eine Ausgabeschicht (Output Layer). Die möglichen Funktionen und Anzahl der Neuronen sowie die Anzahl Schichten sind Teil des Aufbaus des neuronalen Netzes und für bestimmte Aufgaben ausgelegt. Neuronale Netze können komplexe Muster sozusagen intuitiv erlernen, ohne vorher feste Regeln entwickeln zu müssen. Während der Lernphase werden die den verschiedenen Neuronen zugeordneten Gewichtungen geändert, damit die richtige Antwort erzielt werden kann.
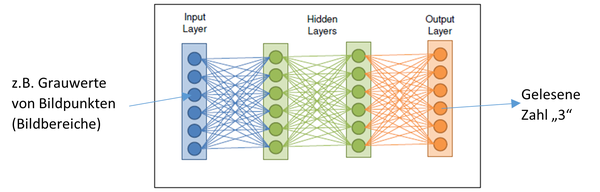
Abbildung 1: Schichtenmodell von neuronalen Netzen
Bei Deep Learning werden zahlreiche verborgene Schichten verwendet und die Deep Learning Netzwerke sind fähig selbständig zu lernen, welche Eigenschaften bzw. Parameter hilfreich sind, um ein richtiges Ergebnis zu erzeugen. Deep Learning dringt erst durch die rasant angestiegene Rechenleistung von CPUs und GPUs und enorme Speicherkapazitäten in die verschiedensten industriellen Bereiche vor. Die Qualität der Ergebnisse hängt letztlich von der Qualität des Trainings und der verwendeten Daten ab. Im Bereich der industriellen Bildverarbeitung sind dies die Bilddaten, die realitätsnah erzeugt und korrekt gekennzeichnet sein müssen.
Die Stärke der heute verfügbaren Deep Learning Tools im Vergleich zu bisherigen konventionellen Tools ist zuerst die enorm gestiegene Leistungsfähigkeit der neuronalen Netzwerke. Die traditionellen Lösungen arbeiten zuverlässig, wenn eine Beschriftung prinzipiell gut lesbar ist und der Druck bzw. die Markierung in wiederholbarer guter Qualität und ausreichendem Kontrast erzeugt wurde. Ausreichend Abstand zwischen den einzelnen Zeichen ist bei den meisten Standardtools ebenso eine notwendige Voraussetzung für sicheres Lesen. Werden die Zeichen durch Verfahren wie Prägen, Nadeln, Ritzen und Lasermarkierung auf verschiedensten Werkstoffen direkt aufgebracht (DPM = Direct Part Marking) oder sind sie in eine Spritz- oder Gussform eingearbeitet worden, kommen die Standardtools schnell an Ihre Grenzen und die Lesesicherheit sinkt.
Die Deep-Learning-Technologie bietet heute die beste Methode zur Lösung dieser Klasse von Inspektionsaufgaben, wenn Codes stark deformiert, schief oder schlecht geätzt sind, wenn der Kontrast zwischen Zeichen und Hintergrund schwach ist, wenn es störende Lichtreflexe gibt, wenn die Zeichen deformiert sind oder sich berühren.
Als ausgereiftes und anwenderfreundliches Deep Learning Tool für OCR Aufgaben ist die Software ViDi Read des Marktführers Cognex hervorzuheben.

Mit ViDi Read lassen sich Beschriftungen lesen, die mit den verschiedensten Verfahren auf komplexe Objekte und Oberflächen aufgebracht sind.
Cognex ViDi Read ist als fertiges Paket auch in der intelligenten Kamera In-Sight D900 integriert.
Anwendungsbeispiele
Lesen von geritzten Fahrzeug Identnummern
Eine Fahrzeugidentifikationsnummer ist ein mehrstelliger Code, der als eindeutige Kennung für Automobile verwendet wird. Sie enthält Buchstaben und Zahlen und kann direkt auf ein Fahrzeugteil aufgebracht sein (DPM); z.B. auf einen metallischen Untergrund genadelt oder geritzt. Reflexe, unterschiedliche Oberflächen sowie Lackfarben und kundenspezifische Fonts erschweren es dem Bildverarbeitungssystem die Zeichen zu erkennen und zu lokalisieren.

Abbildung 2: Eingeritzte Fahrzeugidentifikationsnummer, welche mit herkömmlichen OCR-Methoden nicht robust gelesen werden kann
Cognex ViDi löst diese Aufgabenstellung sicher und ist einfach zu trainieren. Es besitzt einen vortrainierten Universal Font, mit dem die meisten Zeichen bereits gefunden und gelesen werden können. Die Zeichen, die nicht automatisch erkannt werden, können anhand mehrerer, unterschiedlicher Bilder gelabelt und schnell nachtrainiert werden.
Eine sogenannte „Confusion Matrix“ hilft dabei die Lesesicherheit festzustellen. Diese Matrix gibt zudem eine Übersicht über die eingelernten Zeichen, wie viele gelabelt, trainiert und gefunden wurden.
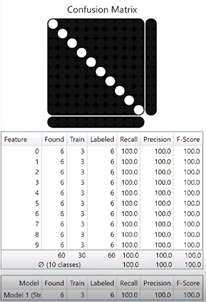
Abbildung 3: Confusion Matrix, welche eine 100%ige Erkennungsrate von numerischem Text darstellt.
Lesen von Codes auf Böden von Aluminiumdosen unter schwierigen Beleuchtungsbedingungen
Getränkedosen sind meist am gewölbten Boden markiert. Aufgrund der glänzenden Oberfläche, der Textur, die bei jeder Dose unterschiedliche Richtung aufweist, sowie der Bodenwölbung ist es zum einen schwierig eine gleichmäßige und konstante Ausleuchtung zu erreichen, zum anderen erzeugt der Tintenstrahldrucker auf der gekrümmten Fläche des Bodens verzerrte Zeichen, unterschiedliche Zeichengrößen und Zeichenabstände.
Cognex ViDi ist in der Lage trotz unterschiedlicher Kontrastverhältnisse sowie verzerrter Zeichen und variabler Zeichenabstände eine maximale Leserate zu erzielen. Auch verschobene oder fehlende einzelne Punkte (Dots), wie sie bei Tintenstrahldruckern vorkommen, stellen kein Problem mehr da.

Abbildung 4: Boden einer Aludose, der durch den gewölbten Boden inhomogen ausgeleuchtet ist. Die Dot-Matrix-Schrift kann in der Qualität variieren und ist eine Herausforderung für herkömmliche OCR-Methoden. Diese Schrift kann mit Deep Learning gut erkannt werden.
Lesen von Laser-markierten Zeichen mit sehr schwachem Kontrast auf einem IC Baustein
Lasermarkierungen, können schwer lesbar sein, wenn nicht ausreichend Zeit für die Markierung zur Verfügung steht, oder das Material keinen guten Kontrast zulässt. Das Ergebnis ist oft ein sehr schwacher Kontrast zwischen Zeichen und Hintergrund.
 Abbildung 5: Selbst Zeichen mit extrem schwachem Kontrast zum Untergrund können mit Cognex ViDi extrahiert und gelesen werden.
Abbildung 5: Selbst Zeichen mit extrem schwachem Kontrast zum Untergrund können mit Cognex ViDi extrahiert und gelesen werden.